
There are two types of alternative sites like the Wayback Machine. First there is a group of services that allows you to look at any website in the past – similar to archive.org. These include archive.is, screenshots.com etc. You can read reviews of them below under the header “Group 1”.
Then there is another group of alternatives that allow you to create a private “Wayback Machine” for specific domains and in the future. Examples include pagefreezer.com and actiance.com. These can be useful if you are a big corporation and you need to be able to keep track of how your website has changed over time (for example for legal reason). You can read about them at the bottom of this article.
This later type wayback machine alternative will probably be used more frequently to create a historic record of someone else’s website – for example, the website of your competitor – or your company’s social media accounts. If it’s your own website, you should have access to the backend, in which case it is easier to use normal backup software.
The second group of software isn’t truly a Wayback Machine alternative, because it doesn’t allow you to look into the past, until after you have configured the software to start tracking your website. However, for specific use case scenarios, it is actually a better option than the Wayback Machine. You have more control, so you can be sure that your entire domain will be fully scraped at regular time-intervals. And if you use it to keep a record of someone else’s domain, you have the added benefit of not having to worry about take-down requests: the Internet Archive accepts take down requests, so your competitor has the power to wipe out all the historic evidence on the Internet Archive.
The above scenarios might sound a bit far-fetched, but they are not. We have a fair portion of lawyers as our customers who need to download archived websites for these type of reasons. Actually, the most common use case scenario for this type of software is legally driven social media archiving.
Let’s go back to the “real” alternatives to the Wayback Machine: the ones that look into the past.
Group 1: The Actual Wayback Machine Alternatives

Alternative 1: Archive.is
Archive.is is the closest thing you can find to the Wayback Machine. In terms of functionality, the website is in-between screenshots.com (see below) and Archive.org. Archive.is saves websites both as a screenshot and as HTML.
Based on a small experiment, their database is about 5% the size of archive.org’s database. It’s not much, but it’s still better than other the alternatives.
- Good for scraping pictures off a domain. Tip: browse an archive and then click “download .zip”
- It doesn’t crawl deep. Usually just the front page.
- Both web page and screenshot. Archive.org could learn from this feature, because many websites have broken stylesheets/css.
- You can download the original HTML, with some limitations.
Database size: 5/10
User friendliness: 7/10
Features: 9/10
NEW: We now also support archive.is. Simply go to our Wayback Downloader and use a link from archive.is, in the same way as you would with a link from archive.org.
Some examples from Archive.is
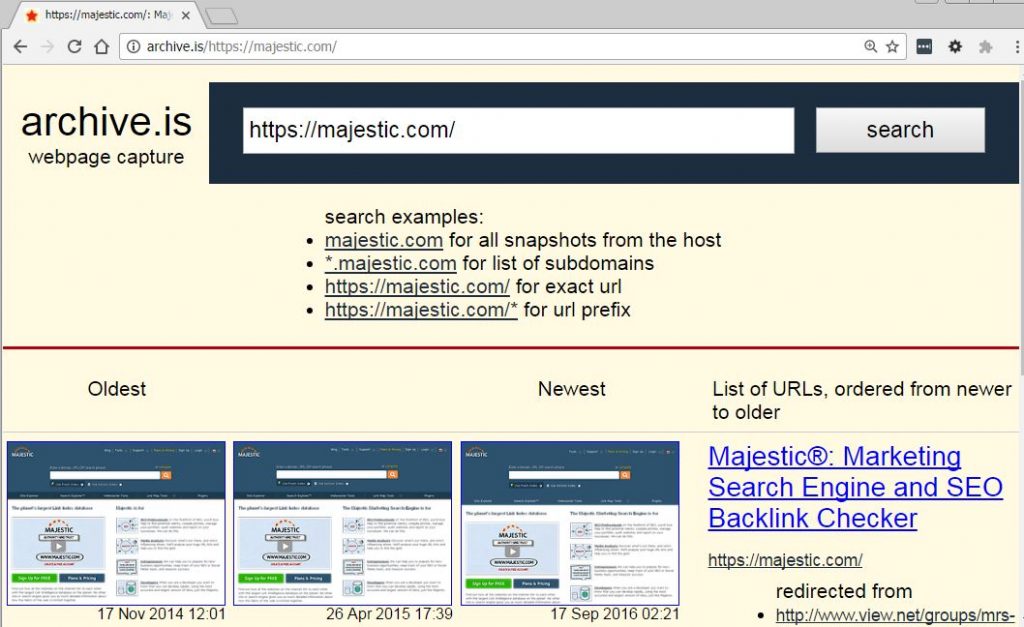
While archive.org crawls the same website on almost a daily basis:
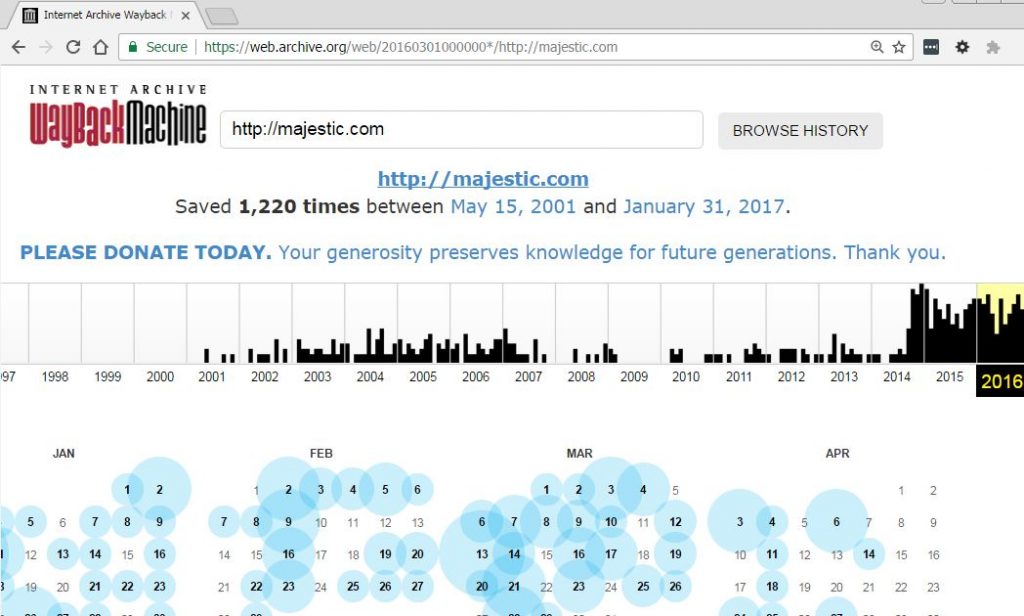
Wayback Machine Alternative 2: Screenshots.com
Screenshots.com has a database of over 250 million website screenshots which, again, is a fraction of Archive.org but it does offer the benefit of the DomainTools API which gives you a greater insight into the history of a website – including when the site’s domain was first registered and how many times ownership has altered.
- It only captures the home page
- Captures ads and images, not the page source code
- Uses DomainTools API
- Screenshots.com links thumbnails of its screenshots to Whois Lookup
Database size: 6/10
User friendliness: 8/10
Features: 4/10
Alternative 3: Webcite
Webcite differentiates itself from the Wayback Machine by offering the kind of specific screenshots of author-cited references demanded by writers, editors and publishers. Google’s and Archive.org’s ‘crude’ approach to archiving limits their ability to do this.
- Archives a cited web page, the HTML and any linked images and documents
- Functionality better suited to the needs of writers and editors
- Clunky interface
Database size: 7/10
User friendliness: 6/10
Features: 7/10
Alternative 4: competitorscreenshots.com
As the name suggests, this archive’s primary use is to compare brands if you’re looking to build a marketing strategy. It’s a combination between an archive.org-clone and a pagefreezer alternative.
You can compare screenshots, email campaigns and social media activity with a free sign up, which gives you access to website data over the previous 60 days. To look back further requires an upgrade – and at $120 per month, it’s not exactly cheap.
- Can compare and track competitors’ websites’ updates and email campaigns
- Free sign up allows you access to basic data
- Limited coverage, particularly beyond .com domain names
- It’s more or less a (very limited) marketing tool for their paid archiving services.
Database size: 2/10
User friendliness: 8/10
Features: 7/10
Group 2: Software to make your own web archive

Online providers that allow you to create your own internet archive.
You may wonder why creating your own Wayback Machine alternative is necessary. After all, if the archive services listed above crawl the web and archive screenshots, code and other meaningful data, why would you need to create your own service?
Essentially it comes down to the value of the data being archived and the level of control you have over it. And while each of the above sites has its own benefits, each has its limitations too. If you want to monitor changes as your online presence evolves, having the facility to look back through screenshots, social media campaigns, data files (Media files, PDF’s, HTML etc.) at any particular time is clearly very useful.
Having access to your own archive means have more control, so you can be sure that your entire domain will be fully scraped at regular intervals. And if you use it to keep a record of someone else’s domain, you have the added benefit of not having to worry about take down requests: the Internet Archive does accept take down requests, so your competitor has the power to wipe out all the historic evidence on the Internet Archive.
But a more pressing concern perhaps is an increase in the need for companies to keep comprehensive records of social media and blog activity. Government departments and the financial sector are acutely aware of the need for such stringent record keeping – they’re required by law to meet a range of regulations. And the threat of litigation around the use, or misuse, of a company’s social media campaign reinforces the message that good record keeping is good practice.
Actively archiving your website – where your data is archived as updates are made – is a growth industry with a few high profile players leading the market. Essentially, you hand over the task of collecting and collating your data, they store it securely and you access it whenever you need to. Social media movements are captured in real time and should you require playback of video or audio, it’s all stored and playable just as it was on the day it was captured. Pagefreezer, Actiance and Socialware all offer archiving services that comply with the relevant regulations although they all vary in their level of provision.
Although it’s tempting to believe your company would never find itself taking legal action for copyright infringement against a competitor, or on the receiving end of a complaint or lawsuit because of an employee’s post on your company’s Facebook page, it has happened and continues to happen. A company’s need to access evidence to prosecute or defend is easily managed if all relevant data is archived.
Clearly, the nature of your business and sector will determine whether your company would benefit from this type of archiving service. It’s essential for some but merely desirable for others. Many online businesses view it as an insurance policy. And like the old insurance motto says: you never think you’ll need an insurance – until you do.